How posix_spawn & close_range “fixed” cold starts
The tale of how we accidentally regressed cold start latency, and how we fixed it

Last November, we had several outages and have since directed much of our engineering efforts towards improving stability. During this phase, cold start latency regressed, but the root cause and magnitude were not immediately apparent to us. We made the call to continue working on stability and revisit the latency issue later.
Today, we want to share the story of tracking down and fixing that regression, which turned out to be in the Pageserver’s walredo mechanism.
Background: Neon Pageserver
The Pageserver is a key component of Neon. It manages the long-term storage and versioning of all the data you store in a Neon Project. When a Compute needs to read a database page, it requests it from the Pageserver, which reconstructs the page from a base page image and subsequent Write-Ahead Log (WAL) records. This task is handled by the walredo mechanism. Before we get into the details, let’s briefly recall the role of WAL in Postgres.
(Learn more about this topic from our earlier post on Neon storage.)
Background: Role Of WAL in Postgres
Postgres employs a redo-style WAL where each entry represents a forward-looking mutation of the database state. For example, such a change could be “insert new tuple number X into page Y with contents Z”.
When Postgres crashes and is restarted, its recovery process determines the point in the log at which it crashed, and replays the WAL from there. Simplifying quite heavily, replay works as follows: first, it initializes the in-memory state to the last on-disk checkpoint; then for each WAL record since that checkpoint, in the order of the WAL, it calls a function that applies the changes described in the WAL record.
Barring a few exceptions that require special treatment, the typical WAL record affects one physical page of a relation.
Background: walredo in Pageserver
Recall that the Pageserver’s primary job is to serve page images to Computes. This task decomposes into two parts: first, the Pageserver needs to store page images and WAL records. Second, it needs to reconstruct page images from that data.
In more detail, the Pageserver queries its storage engine for reconstruct data; that’s the most recent base page image that precedes the requested page version, and all later WAL records that affect that page, up to the requested version. The walredo infrastructure then consumes the reconstruct data, applying all the WAL records’ mutations to that base page image, such that we arrive at the same reconstructed page image at the requested version as disk-based Postgres would.
The difficulty with this task is that the Postgres WAL is not a formally specified protocol with unambiguous semantics for each WAL record. We find that at this time, the only maintainable way to ensure we reconstruct the same page image as disk-based Postgres is to run the exact same code.
The problem: that code is written in a memory-unsafe language (C) and is being fed untrusted input, i.e., WAL records generated by a compute which we must assume is malicious or otherwise compromised.
We can’t run that code inside the Pageserver process: one Pageserver hosts thousands of tenants, and so, a memory-safety bug or a vulnerability exploited by one tenant would affect all the tenants hosted by that Pageserver.
Our solution at Neon is to isolate the redo code into a sidecar process, one per tenant. The sidecars and the Pageserver communicate using a pipe-based inter-process-communication mechanism. We use seccomp to isolate the sidecar process and to minimize the attack surface with the Linux kernel. If you squint at it, the sidecar provides a pure function (page reconstruction) that happens to require an isolated address space for safety. Learn more about the design in the technical docs and code.
We’ll refer to the sidecar process as walredo process in the remainder of this blog post.
The Regression: Changes To The walredo Process Lifecycle
For a long time, the Pageserver started a tenant’s walredo process lazily on the first request and then kept it around until the Pageserver was restarted during a later deployment.
As Neon grew and grew, we wanted to increase the tenant density in our Pageserver fleet. The first constraint was NVMe capacity, which we resolved by implementing offloading of layers to S3. The next capacity bottleneck was DRAM, which brought our attention to the walredo processes: we were only starting but never stopping them, not even if their compute went idle or there hadn’t been requests for a long time.
So, in November, we shipped a change to shut down unused processes after a quiescing period of 200 seconds.
After shipping the above change, our DRAM capacity problems vanished, as expected. We did observe a moderate increase in CPU utilization, but attributed it to other changes and the increased density we were working towards.
In reality, this change regressed latencies of cold starts and first-query-after-200s-idle dramatically. With the dashboard and observability infrastructure we have built since then, it’s trivial to see, but we did not realize the magnitude of the problem at the time. (Note the logarithmic scale of the Y axis)
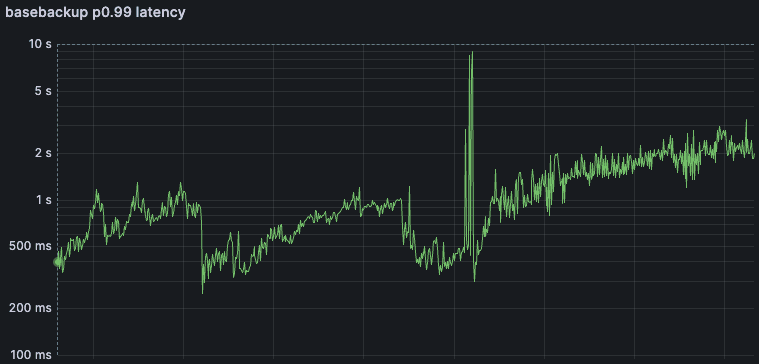
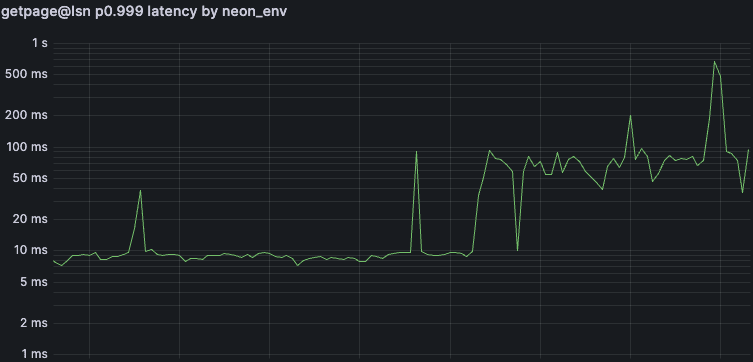
Discovery
There’s no way to sugarcoat it: this latency regression was not properly investigated until a customer escalation drew attention to the problem.
The curious case with that customer was that their compute was used often enough for it to never scale to zero, yet rarely enough that our walredo quiescing mechanism would kick in. The resulting symptom was that the first query after 200s of no queries would often take multiple seconds.
In the past, we had seen such issues with cold starts, i.e., after scaling a compute to zero. Cold starts involve many Neon components, so, it is tempting to discount any problems in that area. But this case was unambiguously a Pageserver problem. Inspecting the project’s Pageserver-side logs revealed that the last message before the slow query was the walredo quiescing. We didn’t log walredo launches at the time, but, there was a metric for walredo process launch latency. It had existed for several weeks, but no alerts had been defined on it. The magnitude of the problem was immediately clear, as the histogram’s buckets weren’t even able to properly capture the majority of observations:
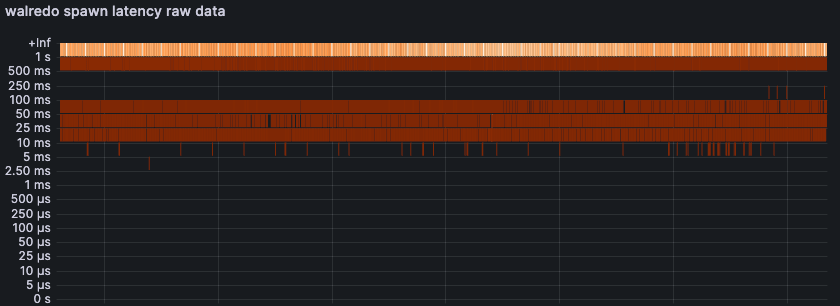
The Root Cause
Spawning a process shouldn’t take multiple seconds. And it didn’t, on less busy production systems, in most of our staging systems, and our developer machines. The obvious difference to the systems where spawning took long was high tenant density, and general business and longevity of the Pageserver process in production.
We used strace to figure out what was going on in the slow production system:
# strace -r=us -ff -p "$(pgrep pageserver)" -e clone,fork,vfork,execve
[pid 5831746] 0.000971 clone(child_stack=NULL,
flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 5831845 attached
, child_tidptr=0x7fa2b34f89d0) = 5831845
[pid 5831845] 2.207960 execve("/usr/local/v15/bin/postgres",
["/usr/local/v15/bin/postgres", "--wal-redo"], 0x7fa21c9bec60 /* 2 vars */) = 0The clone system call is the glibc C library’s fork implementation. And the exec system call is, well, just that.
We were surprised to see fork + exec there, because in the Pageserver, we use std::process::Command to create the walredo sidecar processes. If available, Command uses posix_spawn to create the child process, which is the most efficient method for process creation on Linux.
We quickly figured out why posix_spawn wasn’t being used: in the Pageserver, we want to defend-in-depth against leaking Pageserver file descriptors into the walredo processes. With good reason! If we forget an FD_CLOEXEC somewhere in the Pageserver code, the untrusted walredo child inherits that file descriptor. walredo ’s seccomp rules necessarily allow read system calls, so, if we ever leaked a file descriptor representing another tenant’s layer files, the malicious walredo would be able to read that other tenant’s data.
So, for more than two years, we had been using the std::os::unix::process::CommandExt::pre_exec extension trait along with the close_fds Rust crate, and specifically its cloexecfrom functionality. The pre_exec allows running code in the child process before exec. We were calling cloexecfrom inside pre_exec to set the FD_CLOEXEC flag on all file descriptors except stdin, stdout, and stderr. That would ensure that any potentially leaked file descriptor would be closed on exec, and thus never be accessible to walredo code.
The problem with that approach: when pre_exec is used, the Rust standard library can’t use posix_spawn anymore because that API doesn’t provide the ability to run arbitrary code before exec. So, for all this time, the Pageserver did fork + exec instead.
Our initial conclusion was that the root cause for our latency problems was the use of an inefficient process spawning primitive, so, we implemented a fix based on that.
The Fix
Obviously, the Pageserver should use posix_spawn; but we didn’t want to give up the defense-in-depth aspect of making sure that all the file descriptors were closed.
We considered the following options:
- Pre-spawn a template
walredoprocess as the first thing during Pageserver startup where we don’t have any sensitive file descriptors open yet. When we need a “real”walredoprocess, we’d then call the template to fork again. The tricky bit here is that Pageserver would still need to establish the pipe to the “real”walredoprocess. Solvable, using file descriptor passing over Unix sockets, but, annoyingly complex. - Move the file descriptor closing logic into the
walredoprocess, eliminating the need forpre_execin the Pageserver process. This is safe because we do trust thewalredoprocess initially, before we start feeding it untrusted user data. For example, we did already trust it to seccomp itself prior to accepting reconstruction requests.
We decided to go with option 2. A minor annoyance was that our target glibc version (2.31), doesn’t provide a wrapper for close_range, but our production kernels (5.10) do support the syscall. So, we had to roll our own syscall wrapper. Another downside is that the close_range system call is not portable, so, on macOS, we lost the protection. As macOS is not a production platform for Pageserver, we deferred this aspect to a follow-up issue.
Fix Impact
Here are the two core latency metrics for the Pageserver fleet during the week where we deployed our fix. We observed latency reductions in cold starts (basebackup) from mean ~2s and p99 ~10 seconds to the low hundreds of milliseconds. (Note the logarithmic scale!)
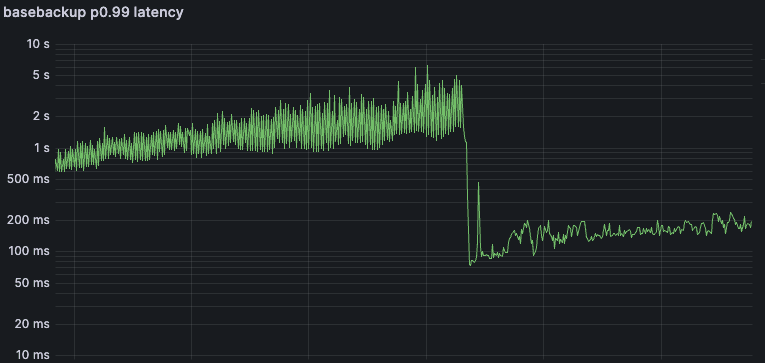
Why Is It Faster, Though?
We thought we had it all figured out. We had shipped the fix to production and were ready to join the club (1, 2, 3, …), praising posix_spawn for a phenomenal win in latency and ultimately UX.
However, some of us rightfully doubted that a ≥ 100x latency win would be possible by switching process creation syscalls. The hypothesis was that actually, closing the file descriptors was what was taking so long.
So, in the process of writing this blog post, we deployed to staging a version with and without the fix and used strace again, this time with syscall timings enabled and the close_range syscall included in the filter:
strace -r=us --syscall-times=us -ff -p "$(pgrep pageserver)" -e clone,fork,vfork,execve,close_range
[pid 3871746] 0.000971 clone(child_stack=NULL,
flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 3877793 attached
, child_tidptr=0x7fa2b34f89d0) = 3877793 <0.091048>
[pid 3877793] 0.092166 close_range(3, -1, 0x4 /* CLOSE_RANGE_??? */)
= -1 EINVAL (Invalid argument) <0.000017>
[pid 3877793] 2.207960 execve("/usr/local/v15/bin/postgres",
["/usr/local/v15/bin/postgres", "--wal-redo", "--tenant-shard-id", "9895f804020c9216c79c829450b73f95"], 0x7fa21c9bec60 /* 2 vars */) = 0 <0.135704>That’s interesting. It’s the familiar glibc fork implementation’s clone syscall, but now we see a failing(!) close_range system call before the execve :
close_range(3, -1, 0x4 /* CLOSE_RANGE_??? */)What’s this? Our distribution’s strace version is too old, it doesn’t know the flag. However, we can browse the linux kernel uAPI headers to find that it’s CLOSE_RANGE_CLOEXEC . The close_fds crate issues close_range with that flag here, as part of its fast path on target_os = "linux" . But for us, it fails. Why? Checking the man page:
CLOSE_RANGE_CLOEXEC(since Linux 5.11) Set the close-on-exec flag on the specified file descriptors, rather than immediately closing them.
We’re running Linux 5.10.
And it turns out that if the call is failing, the close_fds crate falls back to sequential iteration over the open file descriptors, plus one fcntl(fd, F_GETFD) for each and if necessary fcntl(fd, F_SETFD, FD_CLOEXEC). Here is the strace output with the fcntl event enabled:
# strace --relative-timestamp=us -T -ff -p "$(pgrep pageserver)" -e clone,fork,vfork,execve,close_range,fcntl
[pid 735030] 5.229084 clone(child_stack=NULL,
flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 737150 attached
, child_tidptr=0x7fc78586d9d0) = 737150 <0.013806>
[pid 737150] 0.014676 close_range(3, -1, 0x4 /* CLOSE_RANGE_??? */)
= -1 EINVAL (Invalid argument) <0.000011>
[pid 737150] 0.000168 fcntl(3, F_GETFD) = 0x1 (flags FD_CLOEXEC) <0.000011>
[pid 737150] 0.000034 fcntl(4, F_GETFD) = 0x1 (flags FD_CLOEXEC) <0.000011>
...
[pid 737150] 0.000031 fcntl(7505, F_GETFD) = 0x1 (flags FD_CLOEXEC) <0.000011>
[pid 737150] 0.000031 fcntl(7506, F_GETFD) = 0x1 (flags FD_CLOEXEC) <0.000011>
[pid 737150] 0.000091 execve("/usr/local/v16/bin/postgres",
["/usr/local/v16/bin/postgres", "--wal-redo", "--tenant-shard-id", "379d6a61f5cdea32e7bb5b020e14c46a"], 0x7fc918010870 /* 2 vars */) = 0 <0.016760>We see that even on the idle staging machine that we used to reproduce this issue, we had to issue 7500 fcntl calls between the always-failing close_range and the execve call. In our production deployment, we have hundreds of thousands of open file descriptors per Pageserver. Assuming a constant fnctl latency of 11us and a typical 200k open file descriptors, we arrive at the 2.2 seconds of latency that we observed at the start of this investigation.
So, why did our original fix solve the problem anyway? It switched from the close_fds crate, which took its fallback slow-path, to manually issuing the close_range system call. And further, this now happens in the walredo C code, so, all the file descriptors that are marked FD_CLOEXEC have already been closed by execve. Note that the CLOSE_RANGE_CLOEXEC flag never made sense for our manual syscall, so we just use it with flags = 0 , which is supported on Linux 5.10. Here is how the fixed code looks under strace:
# strace --relative-timestamp=us -T -ff -p "$(pgrep pageserver)" -e clone,fork,vfork,execve,close_range
[pid 710496] 5.207816 clone(child_stack=0x7fd5a0139ff0,
flags=CLONE_VM|CLONE_VFORK|SIGCHLDstrace: Process 726067 attached
<unfinished ...>
[pid 726067] 0.003664 execve("/usr/local/v16/bin/postgres",
["/usr/local/v16/bin/postgres", "--wal-redo", "--tenant-shard-id", "379d6a61f5cdea32e7bb5b020e14c46a"], 0x7fd54637b070 /* 2 vars */ <unfinished ...>
[pid 710496] 0.000130 <... clone resumed>) = 726067 <0.003769>
[pid 726067] 0.001070 <... execve resumed>) = 0 <0.001157>
[pid 726067] 0.012868 close_range(3, -1, 0) = 0 <0.000093>Summary & Lessons Learned
In November, we made a change to shut down idle walredo processes to improve tenant density on Pageservers. While that change achieved the goal of higher density, it caused a severe regression in cold start latency. Obviously, that is unacceptable, and we appreciate our customers’ patience while working on the fix.
The initially suspected root cause for the regression was the use of an inefficient process creation primitive (fork+exec instead of posix_spawn ) because we were relying on CommandExt::pre_exec to close file descriptors before executing untrusted code as a defense-in-depth measure.
We moved the closing of file descriptors from Pageserver’s pre_exec into the walredo subprocess. This enabled the Rust standard library to use posix_spawn .
The switch to posix_spawn was believed to be the root cause at first, but actually, the dominant latency component was the inefficient closing of file descriptors that is part of our defense-in-depth strategy against compromise of walredo. In retrospect, the inefficient closing seems like an obvious root cause. The lesson is that reading code is no substitute for dynamic tracing at runtime. Also, we should have had a warning for when close_fds takes its slow path.
As we are preparing our infrastructure to support heavier workloads, the quality of our service is just as important as the mere platform stability. To this end, we continue to
- improve observability by adding more metrics for latency-sensitive operations,
- define internal SLOs & monitoring conformance, and
- allocate more developer time to performance investigations.
Thanks for reading. What applications are you currently building? Try Neon today, join us on Discord, and let us know how we can improve your experience with serverless PostgreSQL.
Appendix
Background: fork, exec, vfork, and posix_spawn
For those less familiar with UNIX systems programming, here’s a short background section on process creation in Unix and Linux.
fork is the oldest method which creates a child process by duplicating the parent. To execute a different program, the child process will then issue an exec system call. Duplicating a process is expensive on CPU and hence latency because the kernel needs to duplicate the parent process’s address space & kernel data structures. Even with fairly standard copy-on-write tricks, the amount of work that fork is effectively proportional to the complexity of the parent process’s OS resource usage. Further reading on problems with fork: “A fork() in the road”, 2019, Baumann, Appavoo, Krieger, Roscoe.
vfork, a later addition, avoids the probably most expensive duplication: the address space. The vforked child shares the parent’s address space until the child calls exec or exits. Until then, the parent process is paused. The child also shares the stack with the parent, so, the child must be extremely careful to not modify it in any way; otherwise, the parent will resume execution on a corrupted stack.
note
💡 The restriction on a vforking child to not clobber the parent’s stack is the reason why CommandExt::pre_exec can’t use vfork: any useful code running in the that closure would need to modify the stack somehow, and as per the definition of vfork, that results in undefined behavior for the parent (see man 2 vfork).
An alternative to vfork is posix_spawn . It’s similarly inflexible as vfork in that it does not allow the caller to run arbitrary code in the child process before exec. However, it provides a well-defined set of operations that are commonly needed by applications that spawn child processes, e.g., signal masking or privilege changes.
Current glibc versions on Linux implement posix_spawn using clone(..., CLONE_VFORK, ...) and a separate stack. This avoids the clobbering problem, although some caveats remain (check the link). It would be worth investigating whether Rust’s CommandExt::pre_exec could follow a similar pattern on Linux, but that’s for another time.
Try It Yourself: CommandExt::pre_exec prevents posix_spawn
Here’s a tiny example program.
fn main() {
use std::os::unix::process::CommandExt;
let mut child = unsafe {
std::process::Command::new("/usr/bin/true")
// comment out this .pre_exec() call for vfork
.pre_exec(|| {
println!("hi from the child");
Ok(())
})
.spawn()
.unwrap()
};
child.wait().unwrap();
}You can use strace to watch:
$ strace -e vfork,fork,clone,execve -f ./target/debug/learn-spawn
With the pre_exec, we get
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLDstrace: Process 982515 attached
, child_tidptr=0xffff91a89500) = 982515
hi from the child
[pid 982515] execve("/usr/bin/true", ["/usr/bin/true"], 0xffffea77d958 /* 41 vars */) = 0
[pid 982515] +++ exited with 0 +++Removing the pre_exec shows glibc’s implementation of posix_spawn , i.e., with CLONE_VFORK:
clone(child_stack=0xffff929e1000, flags=CLONE_VM|CLONE_VFORK|SIGCHLDstrace: Process 982632 attached
<unfinished ...>
[pid 982632] execve("/usr/bin/true", ["/usr/bin/true"], 0xffffda58f618 /* 41 vars */ <unfinished ...>
[pid 982631] <... clone resumed>) = 982632
[pid 982632] <... execve resumed>) = 0


