Incident Review: Pageserver outage in us-east-1
Lessons learned and steps to a more resilient system

On 2024-08-14, about 0.4% of customer projects in us-east-1 experienced an outage for up to 2 hours, after an EC2 instance hosting one of our services failed. We understand that these incidents have a significant impact on our customers, and we take them seriously. This post explains what went wrong, how we fixed it, and what we’re doing to avoid situations like this in the future.
Background
Neon databases are stored on our safekeeper and pageserver services. Read more about architectural decisions in Neon.
Pageservers ingest data from the Postgres WAL stored by safekeepers, and then cache & index it at 8KiB page granularity so that when a Neon compute instance needs to read a page, it can do so in microseconds.
Pageservers can be thought of as a local disk cache: they use S3 for durable storage, so when we lose a pageserver no data is lost, but any projects which were hosted there can become unavailable if Postgres needs to request a page. This can be resolved by attaching that project to another pageserver.

Pageservers in our AWS regions run on EC2 instances. Typically, when one of these is about to experience a hardware failure, we get advance warning from AWS, but occasionally these fail without warning, as happened in the incident on Wednesday. These failures are not a violation of EC2’s API contract: it is our responsibility to gracefully handle sudden instance failures.
The Neon Control Plane manages the lifecycle of user Projects, including assigning them to pageservers, and passing through requests to create and delete Branches.
Sequence of events
- 17:28 EC2 instance pageserver-7.us-east-1.aws.neon.tech became unresponsive. From this time until resolution, customer databases that needed to read data that wasn’t already in their postgres buffer cache would stall.
- 17:38 Alerts fired, notifying our team in slack and paging on-call engineers automatically. In fact, several alerts fired: we detect this kind of failure in several ways: the pageserver stops responding to metric scrapes, the error rate on our control plane API increases, and user operations such as starting endpoints and creating timelines get stuck.
- 17:41 incident declared
- 17:45 engineering team identified that node pageserver-7.us-east-1.aws.neon.tech was at fault, and diagnosed it as a bad node (no metrics, no logs, cannot reach via SSH).
- 17:52 Decision is made to migrate projects on this pageserver to other pageservers in the region. There are 17037 projects assigned to the failed pageserver
- 17:58 Migration starts
- 18:40 99.5% of migrations are complete, approximately 20 projects in unusual states require manual intervention.
- 19:41 All projects available, alerts clear.
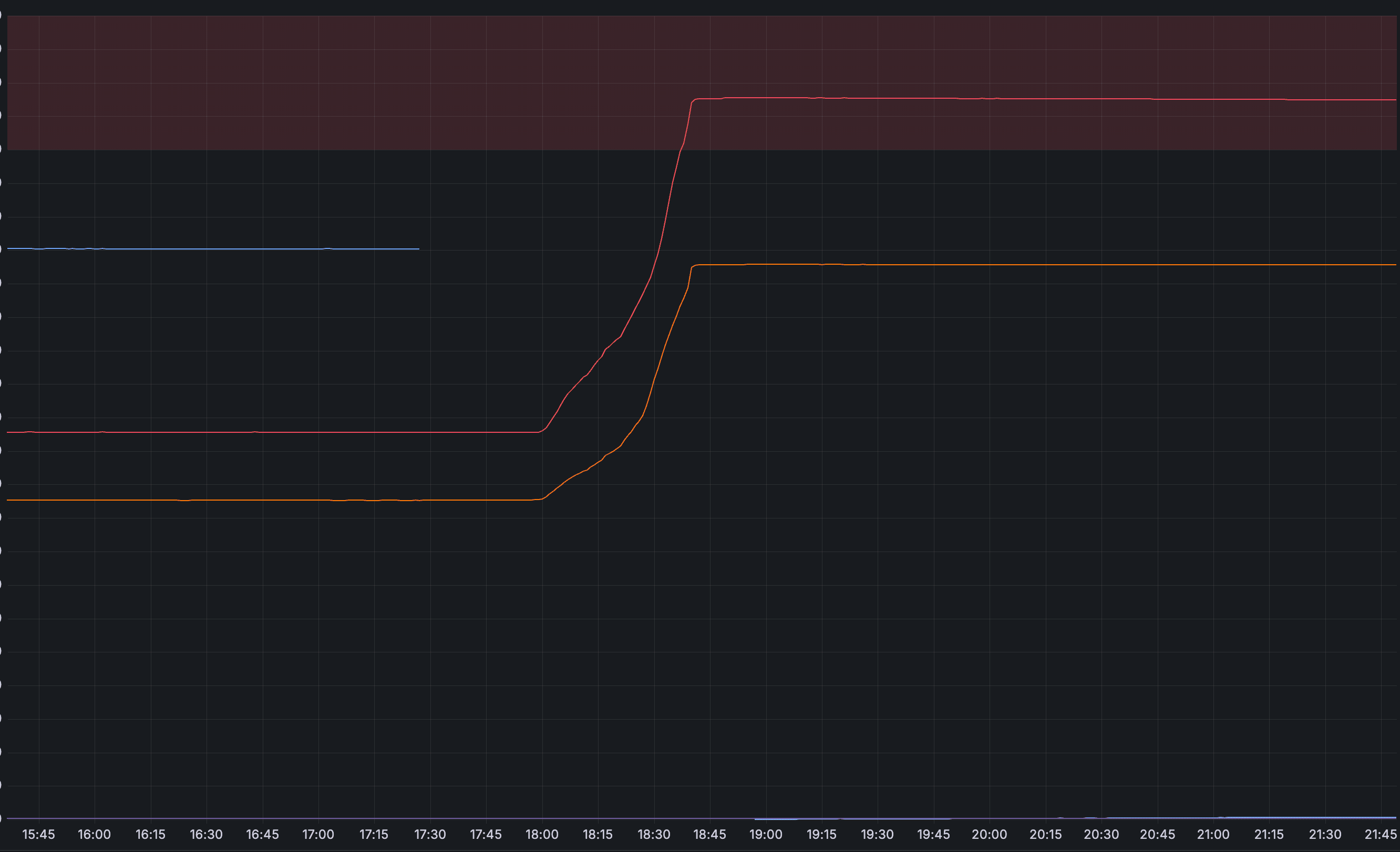
The failure and subsequent recovery may be understood visually using the chart below, which shows the number of Projects attached to each pageserver. The truncated blue line is the failed node, the red and orange lines are the nodes to which projects were migrated.
Note that the number of Projects (internally, “tenant shards”) migrated is much higher than the number directly impacted by the incident: most of these projects were not being actively accessed at the time of the incident.
What took so long?
The incident response worked in that it successfully restored service to all projects, but it took far too long: most impacted customers experienced a ~30-60 minute availability gap, and a smaller number of customers experienced a ~2hr gap.
The causes of the delay were:
- The time between a node failing and the decision to migrate projects away has a human in the loop, and is driven by alerts that have a multi-minute latency to detect loss of telemetry and alert a human. It took around 30 minutes between the initial node failure and the migration starting.
- A semi-manual script is used to migrate nodes away, and this took ~40 minutes to migrate the 17037 projects which were attached to pageserver 7.
- While most projects could be migrated quickly, some were stuck in ways that required manual intervention, as they had operations in flight that blocked migration. These took another ~hour to bring back into operation.
It’s also worth recognizing what went well: although alerts were slower than we’d like, they were accurate and enabled the team to identify the root cause quickly. While migration was too slow, it was robust: there was no data loss, and no split-brain issues. All the projects had secondary pageserver locations prepared beforehand, so we had enough capacity on other nodes, and after migration they already had warm caches and could give good performance.
How are we fixing it?
Some time ago, we recognised that the first iteration of our control plane’s design was not suitable for driving rapid response to node failures at scale.
The control plane’s design may be thought of as a CRUD API with an underlying queue of Operations, where Operations always run to completion, and may execute one at a time per Project. This design works fine when the underlying systems it drives are themselves highly available, but it falls short when managing individual physical nodes, which can fail. The premise that operations will always complete eventually does not hold when those operations depend on physical resources (e.g. EC2 instances) that can stop working at any time.
To resolve this issue, we created a new service: the Storage Controller. The storage controller is designed very differently to the control plane, and was built for anti-fragility and fault tolerance from the ground up, as well as implementing Storage Sharding to support larger databases. The controller uses a reconciliation-loop model to schedule users’ Projects onto pageservers, and to re-schedule them in the event of a failure. Every API call it makes to a pageserver is considered fallible, and in the event of failures, the controller will re-consider its scheduling decisions, enabling it to respond dynamically to changes in node availability or load.
The storage controller uses its own heartbeat mechanism to decide when a pageserver is available, independent of our other monitoring systems and the human-in-the-loop alerting flow. This enables it to respond autonomously and more rapidly, as the intervals between heartbeats are shorter than the intervals between metric scrapes. Failures of nodes managed by the storage controller have a minimal impact on service: the controller responds autonomously and moves work to other nodes in seconds.
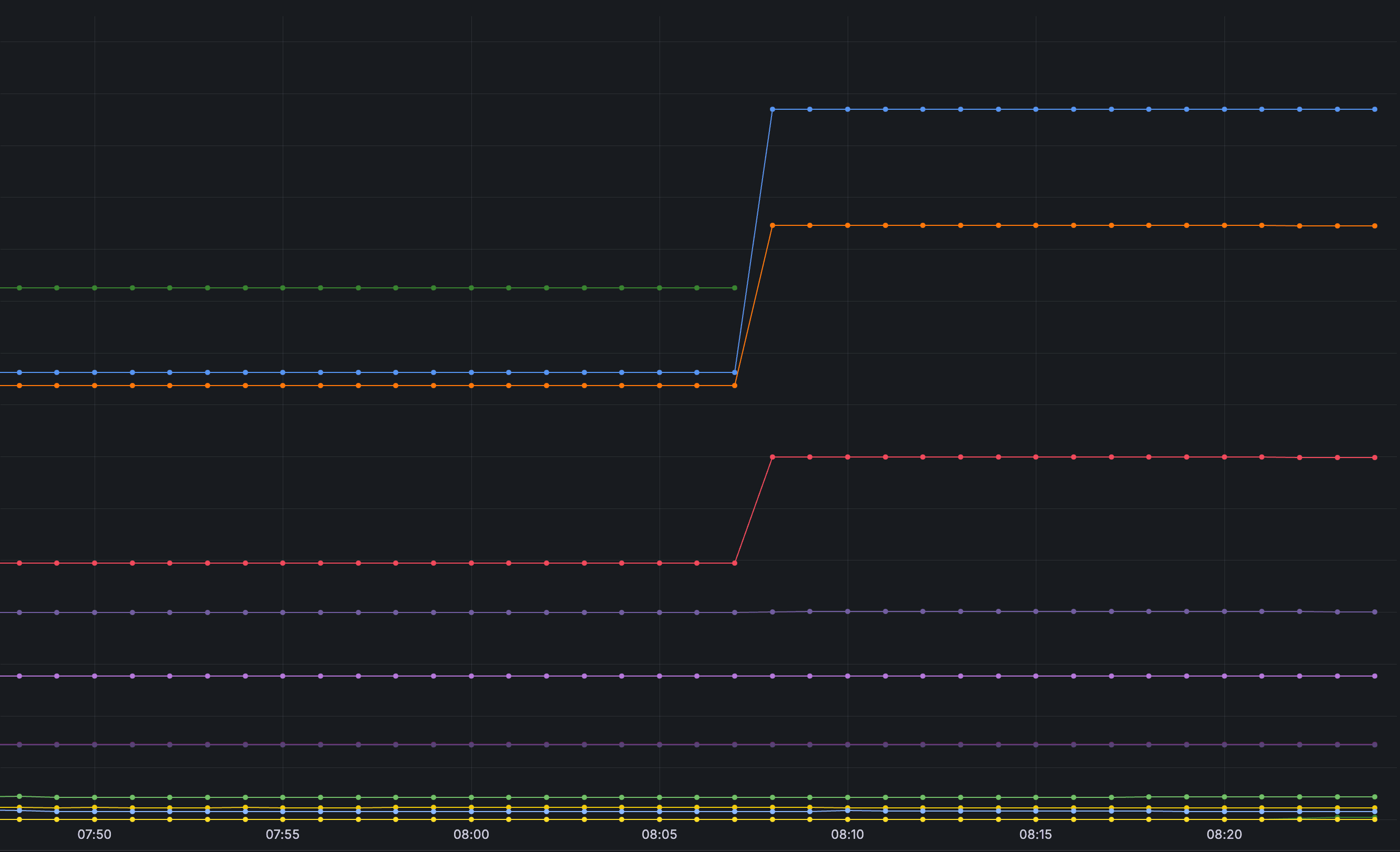
The chart below shows what happens when a pageserver managed by the storage controller fails. We see a node fail (the truncated green line), and by the next metric scrape, all the work that was on the failed node has been migrated to other nodes: this migration starts immediately, proceeds without human intervention, and takes seconds: by the next metric scrape interval, the system is fully restored.
What’s next?
The storage controller has been in production in Neon since May 2024, and we are in the process of migrating our existing pageserver infrastructure to be managed by the storage controller. At the time of the incident, all high-capacity Projects (above 64GiB) were already managed by the storage controller, but the majority of smaller projects were not.
Neon has hundreds of thousands of customer projects under management, and we chose to focus on large-capacity projects first, and gradually proceed in size-order to migrate all the smaller databases to the storage controller. In light of Wednesday’s incident, we are accelerating our plans to move all our paying customers onto the storage controller.
This isn’t the end of the journey: in the future, as our customers move even more critical workloads to Neon, we anticipate providing even faster response times.



