A Guide to Logical Replication and CDC in PostgreSQL with Airbyte
Synchronize your PostgreSQL and Airbyte data with Logical Replication

PostgreSQL is a database that needs no introduction. Started as an open-source project out of UC Berkeley, it has evolved through decades of careful stewardship to become one of the world’s most relied on and beloved relational database management systems (RDBMS).
There will inevitably come a time when the data captured and stored in your PostgreSQL database needs to exist somewhere else. Perhaps you need to replicate data between Postgres servers, to ensure your system survives a critical failure or heavy spikes in traffic. Alternatively, you may need to move your data to an environment better suited for data analysis and activation.
In this blog, we’ll look at how to satisfy both of these requirements using logical replication. We’ll review the internal mechanisms that enable replication in PostgreSQL, compare different types of replication, and finally, provide a guide to efficiently replicate your data between Postgres instances and other data stores.
Let’s jump right in!
What is Database Replication?
Database replication is the process of copying and maintaining database objects (in our case today, tables), in multiple locations. This can happen synchronously or asynchronously, at the byte, block, or logical level, and is crucial for high availability, load balancing, and data activation.
Replication in PostgreSQL is handled by several processes and features. We’ll discuss how these components work below.
PostgreSQL Replication Mechanisms
Let’s look at a couple of the key internal components in PostgreSQL that make replication possible.
The first component to know is the Write-Ahead Log (WAL). The idea behind the WAL is that changes to data files (eg. tables, indexes) must be written to disk only after those changes have been logged. The WAL, then, is that log – an append-only ledger that records every change in the database.
Using a WAL comes with a few benefits. It ensures PostgreSQL can recover from a crash, even if the crash occurs in the middle of a transaction. It also allows for point-in-time recovery. It even assists in PostgreSQL’s implementation of Multiversion Concurrency Control (MVCC) – the WAL keeps a version history of data changes, enabling multiple transactions to occur concurrently, accessing data in the order it was changed based on the query’s start time.
WAL records are created every time a table’s contents are modified. They are first written to the WAL buffer (whose size is determined by the `wal_buffers` settings). By writing to memory first, PostgreSQL can optimize and reduce the number of disk I/O operations. When the buffer is full, the data is flushed to disk as a WAL segment.
Each WAL record entry describes a change at the byte or block level in the database. The insert position of the record is described by its Log Sequence Number (LSN), a byte offset that increases with each new record. WAL files are stored in the pg_wal directory, and are a maximum of 16 MB by default (though this is configurable).
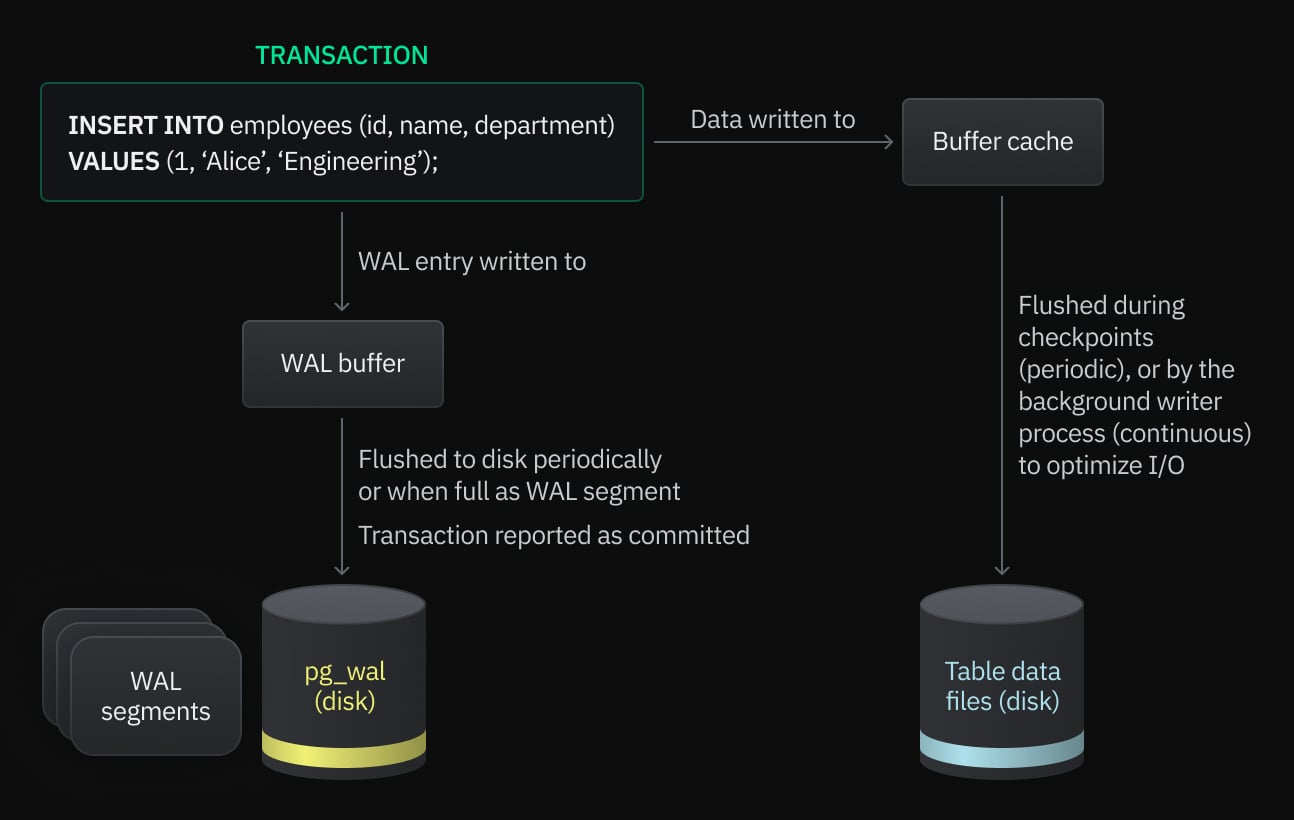
How incoming data and WAL records move through PostgreSQL
Through the process of logical decoding, WAL files can be turned into a readable format that represents high-level database operations like INSERT, UPDATE, and DELETE. So, for example, the record might originally say “byte A in file B was changed to C”, but through the process of logical decoding, it can be read as “row R in table T was updated to value V”. These logical change records can be “published” by a database instance to “subscribers”. After WAL records are flushed to the publisher’s disk, the WAL Sender Process streams the committed WAL segment data to the subscribed standby servers. This, in a (rather large) nutshell, is how CDC replication works in PostgreSQL.
A PostgreSQL database can only have so many subscribers. The relationship between publisher and subscriber is mediated by PostgreSQL’s replication slots. Replication slots are a persistent data structure used to track the progress of replication across subscribers, and to ensure that WAL data needed for replication is not prematurely removed (or recycled). They work by storing the LSN of the WAL record most recently received by each subscriber. When a replication slot is active, PostgreSQL will retain all relevant WAL segments that are necessary for the subscriber to stay in sync with the publisher – even if they are older than the retention policy would normally allow. This guarantees that the subscriber can always catch up, and prevents data loss due to missing WAL segments.
There are two kinds of replication slots in PostgreSQL – physical (for physical replication) and logical (for logical replication). Let’s take a moment to distinguish between the two types of replication, before we cover how to implement CDC between Postgres servers and other data stores.
Physical vs Logical Replication
Replication in PostgreSQL is either physical or logical. Physical replication is at the byte-level. The exact binary data from the master server’s disk are copied to the replica (including, but not limited to, the WAL). Physical replication is typically used when setting up a master-replica architecture. Physical replication in Postgres has native support for streaming, making it useful for setups that ensure high availability via standby servers.
Logical replication, on the other hand, is at the transaction level. Rather than copying bytes off the disk, the logical change records (detailing INSERTs, UPDATEs, DELETEs) are copied over. Because it’s at the logic level, filters can be applied to only replicate specific tables, rows or columns, making it much more flexible than physical replication. Logical replication is ideal for syncing your transactional data to a data lake or data warehouse. Both approaches are suitable for read-replica load-balancing, though logical replication introduces replication lag.
It’s important to note that when using logical replication, the database schema and DDL commands are not replicated. Schema changes must be kept in sync manually. When the schema between producer and subscriber are out of sync, the replication process will error – this can be avoided by applying any additive schema changes to the subscriber first.
We’ll first look at how to replicate PostgreSQL data between two or more PostgreSQL servers, otherwise known as master-replica logical replication. Then, we’ll cover how to replicate PostgreSQL data to OLAP environments for further processing and analysis.
Replicating Data Between PostgreSQL Servers
Load-balancing read requests to replicas is a common approach to reduce the load on your primary database. In this guide, we’ll look at how to implement the master-replica (or primary-standby) pattern using logical replication. In this case, the primary is the publishing PostgreSQL database, while the standbys are subscribers. This approach is only suitable for workloads without hard real-time requirements, as there will always be some degree of replication lag when implementing logical replication.
To set up logical replication following the primary-standby pattern, start by configuring your primary database.
- Edit your
postgresql.conffile to enable logical replication by setting thewal_leveltological, and adjustmax_replication_slotsandmax_wal_sendersto accommodate the number of replicas you need. - Create a user role with replication privileges with the following command:
CREATE ROLE replicator WITH REPLICATION LOGIN PASSWORD 'password';- Edit the
pg_hba.conffile to allow the replication role to connect form the replicas’ IP addresses. - Create a Publication on the primary using the following command:
CREATE PUBLICATION my_publication FOR TABLE table1, table2;
Next, on each standby server, create a subscription with the following command:
CREATE SUBSCRIPTION my_subscription
CONNECTION 'host=master_ip dbname=db_name user=replicator password=password'
PUBLICATION my_publication;Before creating your subscription, you may want to initialize the standby’s database with a snapshot of the primary’s data. This can be achieved with pg_dump and pg_restore, Postgres utilities for backup and restoration.
The above approach is well-suited for PostgreSQL-to-PostgreSQL replication. But what if you need your data in a centralized environment more suitable for analysis?
Several tools exist to help you extract and replicate your data out of PostgreSQL and into analytical stores through logical replication. In the next section, we’ll look at how to do so with Airbyte, the open-source standard for data movement.
Replicating Data Between PostgreSQL and External Data Stores with Airbyte
Airbyte works by providing two connectors – a source connector and a destination connector. These connectors can then create a connection, which is your EL pipeline. Many connectors in the Airbyte catalog are community built and maintained. The PostgreSQL source connector is certified, meaning the Airbyte team maintains the connector, and provides a production-readiness guarantee. You can expect excellent performance as well – check out our replication benchmark against Fivetran to learn more.
To begin replicating your PostgreSQL database, start with steps 1 and 2 from above. Create a replication slot on your Postgres database to track changes you want to sync. Then, create publication and replication identities for each Postgres table you want to replicate. Publication identities specify the set of tables (and, optionally, specific rows within those tables) whose changes you want to publish. Replication identities are configurations on the replica side that determine how the replicated data should be handled or applied.
From there, it’s as simple as walking through Airbyte’s UI to set up your PostgreSQL source connector, and a destination connector (for example, BigQuery, Snowflake, or Redshift). For a more detailed walkthrough, check out our documentation.
Replicating Data Between Neon and External Data Stores with Airbyte
Effectively managing and scaling PostgreSQL deployments in the cloud can be expensive and impractical for smaller teams. Several companies now offer Postgres database maintenance with cloud-native scalability. Neon is one such platform for serverless PostgreSQL. It comes with features you’d expect from a managed cloud solution, like autoscaling and the separation of compute and storage, but also supports advanced features like database branching.
Neon recently added support for logical replication, and is fully-compatible with Airbyte’s CDC solution. Pairing a cloud database like Neon with Airbyte’s own managed offering, Airbyte Cloud, can deliver a scalable, reliable, and low-cost solution for your OLTP and replication needs.
To get started, check out Neon’s documentation on connecting to Airbyte.
Final Thoughts
Before signing off, let’s take a quick look at some WAL configurations you’ll want to keep in mind when configuring your logical replication setup.
wal_compressionis a setting that can minimize the impact of WAL accumulation between Airbyte syncs. As mentioned, once a replication slot is filled, WAL records are kept around until they are successfully published to the subscriber. If there is significant time between syncs and you are storage-conscientious, setting a wal_compression policy will save you on space at the cost of some extra CPU.max_wal_sizesets the amount of disk usage the WAL is allocated between checkpoints. The default value is 1 GB. To ensure a seamless replication experience, set the max_wal_size large enough for the WAL to be easily stored between syncs.min_wal_sizesets the limit at which WAL files will be removed, rather than recycled, between checkpoints. The default value is 80 MB. Adjusting this value to align with your workload can optimize disk space usage and improve replication performance.
PostgreSQL is a time- and battle-tested workhorse. Its robust community, dedicated contributors, and flexible feature-set make it an excellent choice for a wide range of use cases.
Today, we’ve examined how PostgreSQL implements logical replication, as well as how Airbyte can be used in your CDC replication setup. We hope you found this guide informative. If you liked this content, share it with a friend, or reach out to us on LinkedIn. We’d love to hear from you!
Until next time.
Relevant Resources



